Step 1
We need a user account with sudo previlege. If you are using an ubuntu machine you can use ubuntu
You can also create a new user using https://violetstreamstechnology.blogspot.com/2020/10/how-to-create-new-user-in-ubuntu-18.html
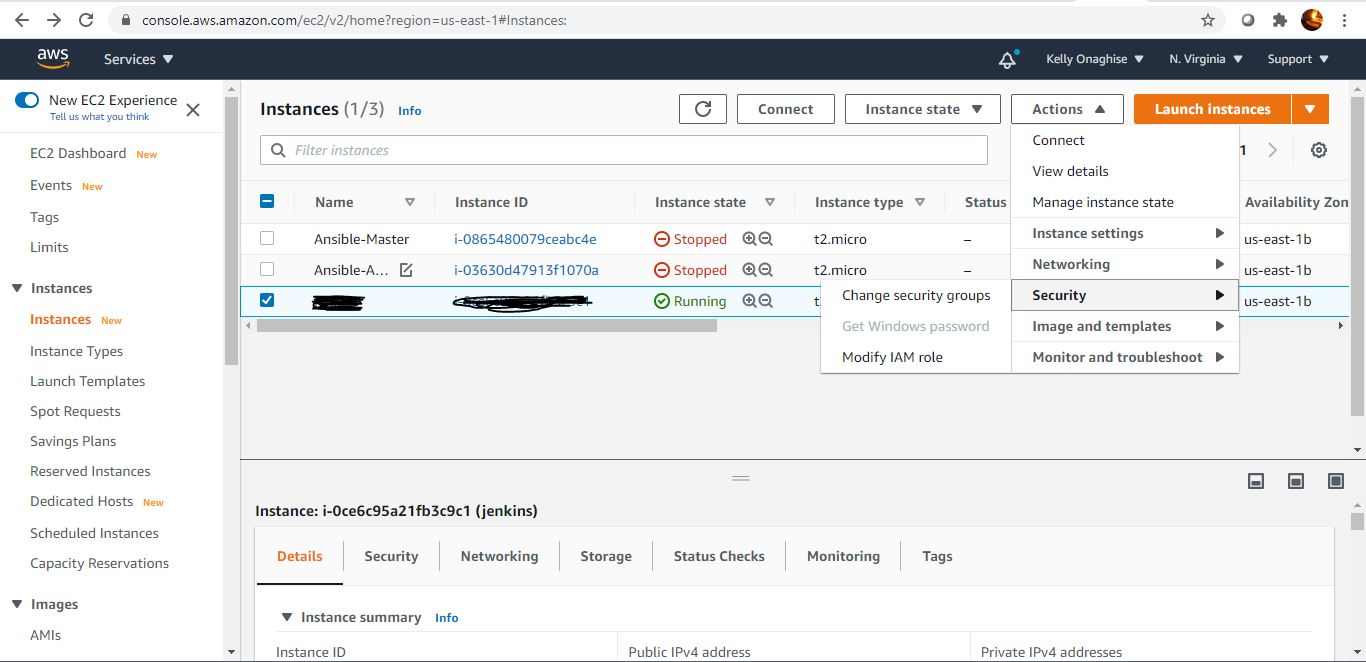
For this lab we will use ubuntu user account. Please launch a target ec2 instance. ubuntu 16.04
Step 2:
Create a password for ubuntu
i. Login to the target ec2 machine
ii. Switch to root
sudo su
iii. Create password for ubuntu
passwd ubuntu
When prompted enter admin for the password
iv. Create password for
root user
passwd root
when prompted enter admin for the password
v. Make sure you enable password login Authentication:(skip this step if you have already done it)
See: https://violetstreamstechnology.blogspot.com/2020/11/how-to-enable-ssh-password.html
Step 3 : Create credentials for bitbucket and Target server
Log into your Ansible Tower Account
Create credentials for Bitbucket
Click Credentials ----"+"
Enter a Name(You can use any name of choice): Bitbucket
Enter Organization: Devops
Credential Type: Source Control
UserName: Your Bitbucket username
Password: Your Bitbucket Password
Then Save
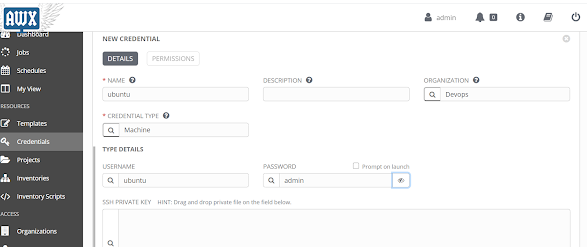
Create Credential for Target server
Click Credentials ----"+"
Enter a Name(You can use any name of choice): Ubuntu
Enter Organization: Devops
Credential Type: machine
UserName: (Username to login to the target server) ubuntu
Password: (Password for the target server)admin
(Note: Make sure you create this user/pswd on the target server-see https://violetstreamstechnology.blogspot.com/2020/11/how-to-enable-ssh-password.html
https://violetstreamstechnology.blogspot.com/2020/10/how-to-create-new-user-in-ubuntu-18.html)
Scroll down---- Enter the parameters for Sudo/root user you will escalate to
PRIVILEGE ESCALATION METHOD
sudo
PRIVILEGE ESCALATION PASSWORD
admin
Then Save
Step 4 : Create a new Project on Ansible Tower( Skip this step if you have created one before)
Click Projects ---- "+" to Add a new Project
You can use the ff details
Name: MyWebAppPackages
Organization: Select an Existing org(You can create one)for this lab i selected Devops
SCM TYPE: Select Git
SCM URL: Enter your bitbucket url
Branch: Enter your bitbucket branch - Ansible
SCM Credential: Select your Bitbucket Credential you created


Then Save
Step 5: Add Target Host to inventory----click Inventories----"+" select ---inventory
Enter Name: Apache(You can Name it anything)
Organization: Devops(Select the organization you created)
Save
Click on GROUPS(Here we can create group of hosts) ----"+" to add a group
Enter Name: Apache-Server
Description: Any description will do (See Screenshot below)
Save
After saving ----Click on Hosts (To Add your target host to the group) ----"+" select---- New Host
HOST NAME: IP of your Target Host
Save
Step 6: Add the playbook to your repo
---Go to your project on your computer
---Open Git bash
---Go into the repo folder : cd myfirstrepo
---launch vscode : code .
----Create a New File
Copy the below Playbook and paste in the New file
---
- name: Playbook to install NGINX
hosts: "{{ deploy_host }}"
tasks:
- name: Ansible apt install Apache
apt:
name: apache2
state: present
Save it as apache.yml
Commit and push to your repo
Step 7: Refresh your project to load the new playbook
Step 8: Create a New Template----click Templates----"+"
Enter Name : Apache-Install
Job Type: Run
Inventory: Apache(Select the inventory you created)
PROJECT: MyWebAppPackages
PLAYBOOK: apache.yml(Select your playbook)
CREDENTIALS: ubuntu(Select the credentials you created)
VERBOSITY: Select 4
In EXTRA VARIABLES Add the deploy host(Specify the group server name or host ip)
deploy_host: Apache-Servers
This will install Apache Server on your Target Host
Go to the Ip Address. Open port 80 and you should see Apache running
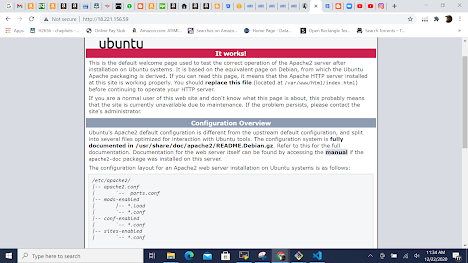
You can try these steps to install more packages with the following paybooks:
Remove Apache:
---
- name: Playbook to install APache
hosts: "{{ deploy_host }}"
tasks:
- name: Ansible apt install Apache
apt:
name: apache2
state: absent
Install Openssl-update cache
---
- name: Playbook to install NGINX
hosts: "{{ deploy_host }}"
tasks:
- name: Ansible apt install open ssl
apt:
name: openssl
state: present
update_cache: yes
Install Nginx
---
- name: Playbook to install NGINX
hosts: "{{ deploy_host }}"
tasks:
- name: Ansible apt install nginx
apt:
name: nginx
state: present
Install Jenkins
---
- name: Playbook to install Jenkins
hosts: "{{ deploy_host }}"
tasks:
- name: Install OpenJDK Java
become: yes
apt:
name: "{{ item }}"
state: present
with_items:
openjdk-8-jdk
- name: ensure the jenkins apt repository key is installed
apt_key: url=https://pkg.jenkins.io/debian-stable/jenkins.io.key state=present
become: yes
- name: ensure the repository is configured
apt_repository: repo='deb https://pkg.jenkins.io/debian-stable binary/' state=present
become: yes
- name: ensure jenkins is installed
apt: name=jenkins update_cache=yes
become: yes
- name: ensure jenkins is running
service: name=jenkins state=started
Install Tomcat
---
- name: Playbook to install TOMCAT
hosts: "{{ deploy_host }}"
tasks:
- name: Install Tomcat 9 on Ubuntu
become: yes
apt: pkg={{ item }} state=latest update_cache=yes cache_valid_time=3600
with_items:
- tomcat8
Install Maven
--- - name: Playbook to install MAVEN hosts: "{{ deploy_host }}" tasks: - name: Install Maven using Ansible become: yes apt: name: maven state: present
Install LAMP stack(ApcheMysqlPhp)
---
- name: Playbook to install Jenkins
hosts: "{{ deploy_host }}"
tasks:
- name: Install LAMP stack using Ansible
become: yes
apt:
name: "{{ packages }}"
state: present
vars:
packages:
- apache2
- mysql-server
- php
You can also download other Playbooks from the internet and use