Ansible Vault is a feature of ansible that allows you to keep sensitive data such as passwords or keys in encrypted files, rather than as plaintext in playbooks or roles. These vault files can then be distributed or placed in source control
Remember of previous tutorial on How to create EC2 instance with Ansible : https://violetstreamstechnology.blogspot.com/2020/09/how-to-create-ec2-instance-using.html
If you notice we had the aws_secret_key and aws_access_key placed as extra variables in Ansible Tower
This is not the best practice. Best practice is to encrypt the access_key and secret_key using Ansible vault to hide this sensitive data.Lets do this to make our project comply with best practices:
Step 1:
Create a vault credential
Create the “Vault AWX” vault credential.
Left Menu (Credentials) > click [+] > Fill the form > click [SAVE]
Give name as access_key: Any name will work
VAULT_PASSWORD:Give it any password you desire: For this tutorial you can use:admin123
Step 2: Encrypt the access_key and secret_key stringsstep 2.1 :Log into the Ansible Tower machine
step 2.2: Use the below command:
ansible-vault encrypt_string "AKIAXR5FQWYQMB" --name "access_key"
Replace Highlighted green above with your access_key
You will be prompted for password. use admin123
You should get result like below:
Copy the encrypted output and save in a notepad(see eg below, copy text in green)
access_key: !vault |
$ANSIBLE_VAULT;1.1;AES256
32666533393238663538663035343932386637386562383830363963643163356537646161316565
6631303132633362663138313334653531306230333866310a373866356135623732613765643234
31643430313236306664376633356564343639376637323832323832313036346231353964336236
6435313139666530380a316331633837376263613637623630633033343734333839326234396131
30303933623736393735393762353863333262313431663130643235636663663236
If you get an error like
Error reading config file (/etc/ansible/ansible.cfg): File contains no section headers.
file: <???>, line: 9
u'collections_paths = /home/ubuntu/.ansible/collections/ansible_collections\n'
open /etc/ansible/ansible.cfg with vi editor and insert
collections_paths = /home/ubuntu/.ansible/collections/ansible_collections below [Default] header
$ sudo vi /etc/ansible/ansible.cfg
Step 3: Repeat the same process for secret_key: we will use same password:admin123
Step 4: Go to your Playbook from previous exercise, Extra Variables And Paste the encrypted variable
---
- hosts: "{{ host }}"
gather_facts: true
vars:
access_key: YOUR_ACCESSKEY
secret_key: YOUR_SECRETKEY
tasks:
- name: Provision instance
ec2:
aws_access_key: "{{ access_key}}"
aws_secret_key: "{{ secret_key }}"
key_name: "{{ pem_key }}"
instance_type: t2.micro
image: ami-03657b56516ab7912
wait: yes
count: 1
region: us-east-2
Replace your accesskeys and secret keys variables with the encrypted string u copied from vault
New playbook should look like below:
---
- hosts: "{{ host }}"
gather_facts: true
vars:
access_key: !vault |
$ANSIBLE_VAULT;1.1;AES256
34376266633337386531356334323464633063633238356564623535653733346531663638393833
3439633230316565363365326436313063363865396565640a306136623863383365613231396166
64303062633561306338346364633132656435396166623361666534353730616365383134663532
3934363563613764310a313661643034666530663235316438336266663833323933343562306337
64343738633030346537386363653464616166343832616561336231313763616266
secret_key: !vault |
$ANSIBLE_VAULT;1.1;AES256
37333631633938653231633238353434373063663865666434343266383636346336343936643336
6338316330316461336365373165313163363432333630360a343334316665643336333762363665
62383035383534386238376363373339666531613262376239393466653234376330326138633239
6361646661323037640a306530663331616339343062333164366666343263383332333962643936
31316338653139633837303563396463313461343232396166346664376230316565376330356166
3436366138363430653838313064653563653731626539306664
tasks:
- name: Provision instance
ec2:
aws_access_key: "{{ access_key}}"
aws_secret_key: "{{ secret_key }}"
key_name: "{{ pem_key }}"
instance_type: t2.micro
image: ami-03657b56516ab7912
wait: yes
count: 1
region: us-east-2
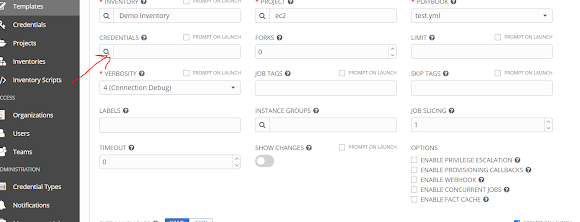
Step 5: In Templates go to credentials Section
Select your Vault credentials for access_key
Save and run your template. The playbook will use the new encrypted variable